
Beautiful Soup(მონაცემთა ამოღება HTML ცხრილიდან)
ამ გაკვეთილში გამოვიყენებთ Beautiful Soup-ს რათა ამოვიღოთ მონაცემები HTML ცხრილიდან.
ქვემოთ მუცემულია HTML-ში მარტივი ცხრილის სტრუქტურა
<table class="my-table" style="width:100%">
<tbody>
<tr>
<th>Firstname</th>
<th>Lastname</th>
<th>Age</th>
</tr>
<tr>
<td>Jill</td>
<td>Smith</td>
<td>50</td>
</tr>
<tr>
<td>Eve</td>
<td>Jackson</td>
<td>94</td>
</tr>
</tbody>
</table>
მოცემული კოდი ვიზუალურად ამგვარად გამოიყურება

პრაქტიკული სავარჯიშო
ამ დავალებაში ჩვენ ამოვიღებთ ცხრილს Wikipedia-ს სტატიიდან. სახელწოდებით The World’s Billionaires
ვიზუალურად ცხრილი ამგვარად გამოიყურება
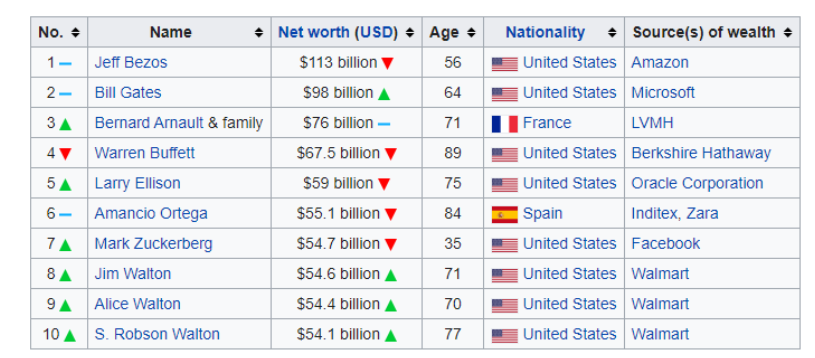
ჩვენ დავწერთ კოდს, რათა შემდგომში მარტივად მოხდეს მონაცემების დამუშავება
გადაწყვეტა
- პირველ რიგში ვხსნით შესაბამის გვერდს inspect ინსტრუმენტის დახმარებით და ვნახულობთ სტრუქტურას

2.ვახდენთ ცხრილის დამუშავებას python-ის დახმარებით
# Importing the Libraries
from urllib.request import urlopen
import pandas as pd
from bs4 import BeautifulSoup
print('** STEP 1 COMPLETED "Analyzing the Markup" **')
# Inializing the Soup object
wikipedia_link = "https://en.wikipedia.org/wiki/The_World%27s_Billionaires"
html_page = urlopen(wikipedia_link)
soup = BeautifulSoup(html_page)
print('** STEP 2 COMPLETED "Retrieving the HTML" **')
# Retrieving the desired Table
billionaires_table = soup.find("table", class_="wikitable sortable")
table_body = billionaires_table.find("tbody")
print('** STEP 3 COMPLETED "Retrieving the relevant Table" **')
# Parsing the <tr> tags to retrieve the relevant stuff
count = 0
data = list()
table_rows = table_body.find_all("tr")
for row in table_rows:
if count == 0:
# As the first <tr> contains the Header of Table
cols = row.find_all("th")
count = count + 1
else:
cols = row.find_all("td")
cols = [elem.text.strip() for elem in cols]
data.append([elem for elem in cols if elem])
print('** STEP 4 COMPLETED "Parsing the Rows to get data" **')
# Constructing the Dataframe from the extacted rows.
dataframe = pd.DataFrame(columns=data[0])
for i in range(1,len(data)):
dataframe = dataframe.append(pd.Series(data[i], index=data[0]), ignore_index=True)
print('** STEP 5 COMPLETED "Constructing the Dataframe" **')
print("The constructed Dataframe is \n")
print(dataframe.to_string())

Python-ზე პროგრამირება ნაწილი 4
ლოჯისტიკური რეგრესია: ნაწილი 2
Optimization and Regularization of Neural Networks
One Comment
pd.read_clipboard()
ეს ცხრილი პირდაპირ დატაფრეიმად გადაიქცევა 🙂